
Editor’s note: Calen discusses the system migration issues Jollibee faced that allegedly led to inventory issues for the fast food giant. Here’s his take on what went wrong and what could’ve been done right.
Last week, a system migration caused problems in inventory deliveries to Jollibee stores, and even outright shutdown of 72 stores. According to this article, Jollibee suffered a sales loss of 6% for at least the first seven days of August. Calculating using Jollibee’s 2013 revenue, this loss amounts to at least a whopping Php 92 million! And considering that the project reportedly already costs Php 500 million, this whole debacle looks like it will cost Jollibee Php 600 million, not including the cost of all the man-days that Jollibee’s management and staff are probably devoting to fixing this problem.
I asked some of my friends in the industry (who shall not be named) on their take on what happened. Below is the information I got so far, and I’ll update this post as I get more information. I’ve also reached out to some friends in Jollibee hoping to get some inside information.
Please note that none of these are from official statements. If anyone wants to provide me with more accurate information on this, or better yet, official statements from the parties concerned, please send me a message and I will gladly incorporate it into the article. My objective here is to provide lessons to the IT and business community so that we can hopefully avoid the all-too-often costly mistakes of IT projects in the future.
The Issues
1. Rip and Replace
Jollibee had originally been using an Oracle product for managing its supply chain – including deliveries of supplies to stores. Because of a dispute with Oracle, Jollibee decided to move its entire supply chain over to Oracle’s rival in this space, SAP.
Now, supply chain software isn’t just out-of-the-box products that you can just install and run. These need to be customized heavily in order to fit a company’s business processes, which usually takes months if not over a year of programming and configuration just to get started. The Oracle system had been running in Jollibee for years, and most certainly had a huge amount of complex programming and configuration from continuous modifications over time. These programs and configurations would have had a lot of fragile interrelationships between them, that made it a huge and risky task to migrate over to the SAP system
2. Staffing and Expertise
The project was outsourced to a large multinational IT service provider. Upon my interviews with members of the Philippine SAP community, they expressed doubt that the Philippine office of the service provider had a sizable local SAP team, if any. They have never heard of that vendor taking on Philippine projects using SAP before, which is why they concluded that the vendor did not have a significant local SAP practice.
My friends further reported that last year there was a large flurry of recruiting activity for SAP professionals from recruiters for that vendor. One of my friends considered this a “red flag”, meaning that the vendor seemed to be having trouble filling the positions required for the project, which is not surprising considering how high the demand for SAP skills are, and how small the supply. Eventually, the vendor allegedly brought in people from India and other countries to staff the project. Based on when the flurry of recruitment activity subsided, my friends estimate that the project was only properly staffed late last year.

Assembling a large team of outsiders quickly is troublesome. They have not worked under a common methodology and culture. They don’t have a common understanding of standards and processes. Any leaders in the group would be overwhelmed from the tasks of understanding the client’s business and designing solutions for the client’s requirements, working with other leaders to agree to common standards and processes, and then organizing and training teams to adhere to those common standards and processes, and then explaining client requirements and overseeing the quality of work.
3. Schedule and Size
This is a half-a-billion-peso project, yet it seems that the project is only operating on schedule of just a little over a year, based on when the recruitment activity started, and when the production issue broke out. Just to give this some perspective, many of the projects I’ve seen costing just 1/20 of this one usually have a two-year timetable. I’d expect that a project of this size would require three to five years to properly implement, from inception to transition.
Maybe this was just a first phase, but unfortunately for Jollibee it has already been a costly first phase. Let’s hope some methodology changes have already taken place to avoid costly mistakes in the future.
4. Testing
Ok, my notes here are not specifically about this project, but about ERP projects in general. As one of my friends pointed out, “You’d be surprised at what passes for unit / functional / integration testing in Oracle and SAP projects.”
Granted, testing is still a terrible area even in Java or .Net projects, but the practices have slowly been gaining ground and maturity over the last ten years. Successful projects often plan and implement tests from the beginning of the project and throughout, not just at the end, with the majority of the tests automated. Testing is elevated to a core part of part of the project, not just auxiliary to programming.
Recommendations
1. Start Small
I’ve been in the situation where I have been asked by existing clients or potential clients to accept large fixed-scope projects, often on compressed schedules. In such situations, we usually respond by proposing only a smaller-scoped project, one that can be accomplished in around six months, by a team of five people or less. The only exception is if the large project is similar to a project we’ve done before, for the same client.
This is an extremely risky move on our part, since normally, clients are dead set on a large scope, and will only consider vendors that meet the complete scope. However, we do this because it is in the best interest of the client and us as the vendor.

First of all, requirements are never right. Almost all fixed-scope projects go through a series of change requests after the project. It is just impossible to correctly imagine upfront all the requirements needed for a project, even for small projects. The only time people realize what they really need is when they actually see the product, or get to use it.
A small initial project would allow the clients to better understand what they really need, and then specify succeeding scope based on something they can see and use. This is similar to the Singaporean government’s “Call for Collaboration” approach, where they invite multiple vendors to build paid prototypes in response to specific problems, which becomes the basis for the full project scope.
Second, it allows the vendor to field a seasoned team. Instead of scrambling to staff a large project, the vendor can source existing people within the company, led by one or more senior people, and having a common methodology. This allows the team to focus on the project concerns instead of having to deal with culture and process issues.
Third, scaling becomes easier later on. After the first project with a small seasoned team, both client and vendor learn about how each other works and how to best work with each other. This allows them to take on larger projects together in an efficient manner. The members of the initial team can be the seed members of new teams, to take on succeeding projects. Those that participated on the first project on both sides can pass on their learnings to others to improve the chances of success of succeeding projects.
2. Testing is Core & Automated
The approach of Test-Driven Development has its origins in 1999, and since then the open-source community has produced a rich set of tools to deal with the various aspects of test specification and automation – from functional testing, to user-interface, to data and integration, to performance.
The most effective teams have testing as part of the core of their methodology. Teams start the project by defining tests, and then define and run tests throughout the project, not just towards the end. Testing is not relegated to just “testers” or QA personnel, but is an activity done by all practices in their own ways – developers, for example, build numerous automated tests around each significant unit of logic, modeling various scenarios.
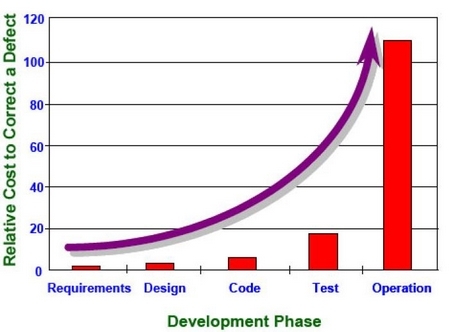
The benefit of this is that as the project moves along, the team builds up a large and rich set of automated tests, that are able to catch bugs early and often, when they are still easy and cheap to fix. Because the majority of these tests are automated, they can be run several times a day and give the team instant feedback.
Let me repeat this fact – defects are cheaper to find and fix if they are found sooner rather than later. Certainly, the defects in the current Jollibee project would have been cheaper had they been found during development, rather than during production, where they are now costing Jollibee millions of pesos a day.
After the system is built, it would naturally go through further enhancements and modifications. These changes can introduce defects. However, the robust suite of automated tests that were created with the system would improve the chances of catching these defects, making it safer and cheaper to maintain the system in the future.
3. Continuous Delivery
One of the riskiest things I see organizations do time and time again, is a big cut-over to a new system. They have a big announcement that, “System X will go live by __!” When that day does come around (usually delayed), it’s invariably a mess! People are unable to get their work done with the new system. If they’re lucky, the old system is still around for them to fall back to, while the new system undergoes bug-fixing. If they’re not lucky, the old system is no longer available either.
Compare this to how Google or Facebook roll out their changes. Notice that your GMail or Facebook has new features that come out every few weeks or months. If you don’t like the feature, there’s a button that allows you to roll back to the old way of doing things. This button is Google’s and Facebook’s way of getting feedback from their users. They roll out the new features to just a partial set of users. If the users opt to roll back, then Facebook and Google know they still need to improve the feature. Then they roll it out again to another set of users. When they hit the point when few users opt to roll back, then they know they’ve got the feature right and make it a permanent part of their systems.
You can apply this to corporate systems. Don’t roll out your systems in big bangs, rather have a lot of frequent rollouts every few weeks or months, to initially a partial set of users, and then gather feedback. It will be easier and safer to roll back small increments of change rather than large ones. Even the deployment and roll back can be automated. This will certainly be less costly to the productivity of your people and the operations of the company.
4. Visibility Through Process & Tools
My final piece of advice sort of puts everything together so that clients can monitor the progress of a project, and catch problems earlier rather than later. A good, responsible team provides visibility to its client. And this visibility is provided via concrete evidence, not status reports that can be faked.
Regular Demos. A good team can provide their client with working software, as often as every one or two weeks. These aren’t PowerPoint presentations. Instead, they’re demos of new features to the software that clients can try out and give feedback on.
Test Reports. Automated tests can and should be run multiple times a day, usually using centralized systems called “Continuous Integration Servers”. These systems can provide clients several times a day with reports on the various tests, and whether they pass or fail. Some of these tests, known as “Acceptance Tests”, are readable by non-technical users, so you can see what behavior is being added to the system, and whether the system already complies with the behavior.
Quality Metrics. Aside from test reports, various tools can be added to the Continuous Integration Server to generate other reports. Among these reports are metrics on quality – For example, in Java there are various tools that can check if the code contains violations of coding standards, or contains logic that is too convoluted, or contains code that often leads to bugs.
Big Visible Charts. If the team works onsite, various charts in the team work area can give the rest of the organization an idea of the progress of the team. Two of the more popular charts are Task Boards and Burndown Charts.
Wrap-Up
The worst part about this case is, this is normal. Huge projects blow up all the time, in fact the bigger the project, the more likely that it will fail. The only difference here is that this one hit the public eye, which is good, since now we get to talk about what causes success and failure in IT projects. I hope the Filipino IT community moves forward with continued discourse and reflection, so that in the future IT projects deliver value to its stakeholders, instead of frustration and waste.
Share





Key Topics

Article
Women Who Code: Transforming the Tech Landscape with Diversity and Skill
Key Takeaways Introduction Over the years, gender inclusivity has constantly been a subject of dispute...

Article
Embracing EQ in UX: A New Era for the Philippines National Skills Framework
Key Insights Introduction The Philippines has long stood as a bastion of warmth and understanding,...

Article
Transforming Tech Talent: Philippines Introduces Game-Changing National Skills Framework for IT Excellence
In today’s rapidly advancing technological world, the gap between academic learning and industry requirements in...
